The SGLang project introduces clever optimizations for LLM inference. In this post, I’ll walk through two key concepts: RadixAttention for automatic KV cache reuse and Overlap Scheduling for maximizing GPU utilization, by studying the mini version of it: mini-SGLang.
RadixAttention: Automatic KV Cache Reuse
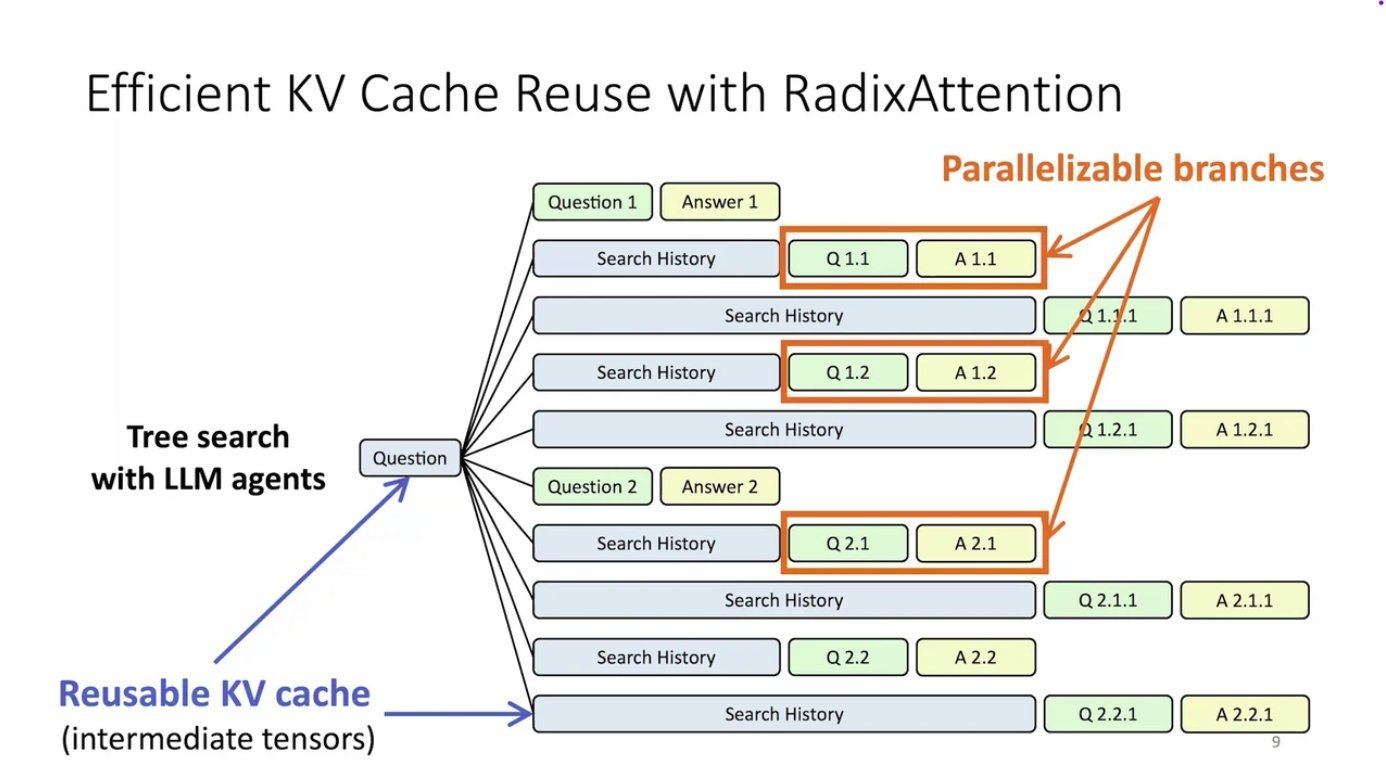
The use of radix tree in SGLang for automatic KV cache reuse is very clever.
Imagine you’re reading the Harry Potter series, one massive book at a time (say, Order of the Phoenix, which is over 800 pages long). Every time you turn to a new page, would you go all the way back to page 1 and reread every single word you’ve already read just to understand the new sentences at the bottom? Of course not.
Yet this is exactly what traditional LLM inference does—recompute 98% of the same work over and over.
How the Radix Tree Works
Think of a tree structure like this:
- The root represents the system prompt
- Branches are different chats or queries
- Shared prefixes are stored just once and reused by multiple branches, saving space and computation
The radix tree is dynamic—it automatically expands with new branches as conversations continue, and trims unused parts when memory needs to be freed.
Let’s walk through an example using multi-turn conversations and few-shot learning queries.
Step 1: Initial State
The radix tree starts empty.

Step 2: First Request
When a user sends “Hello” and receives “Hi”, the system prompt “You are a helpful assistant”, the user message “Hello!”, and the LLM reply “Hi!” are consolidated into the tree as a single edge linked to a new node.

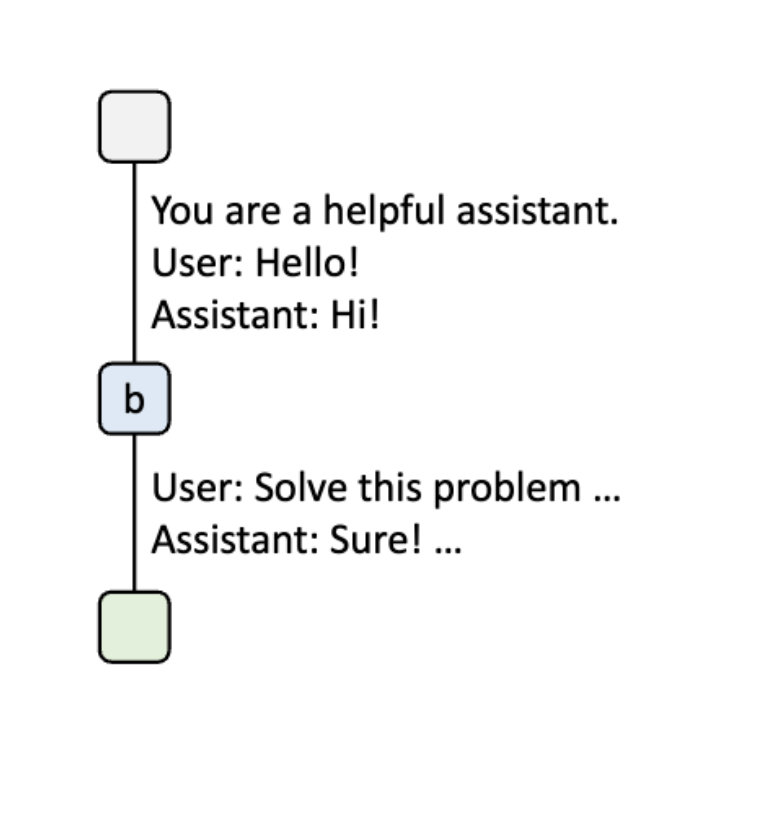
Step 3: Reuse Shared Prefix
When the user sends a new prompt in the same conversation, the server finds the prefix of the prompt in the radix tree and reuses its KV cache. The new turn is appended to the tree as a new node.
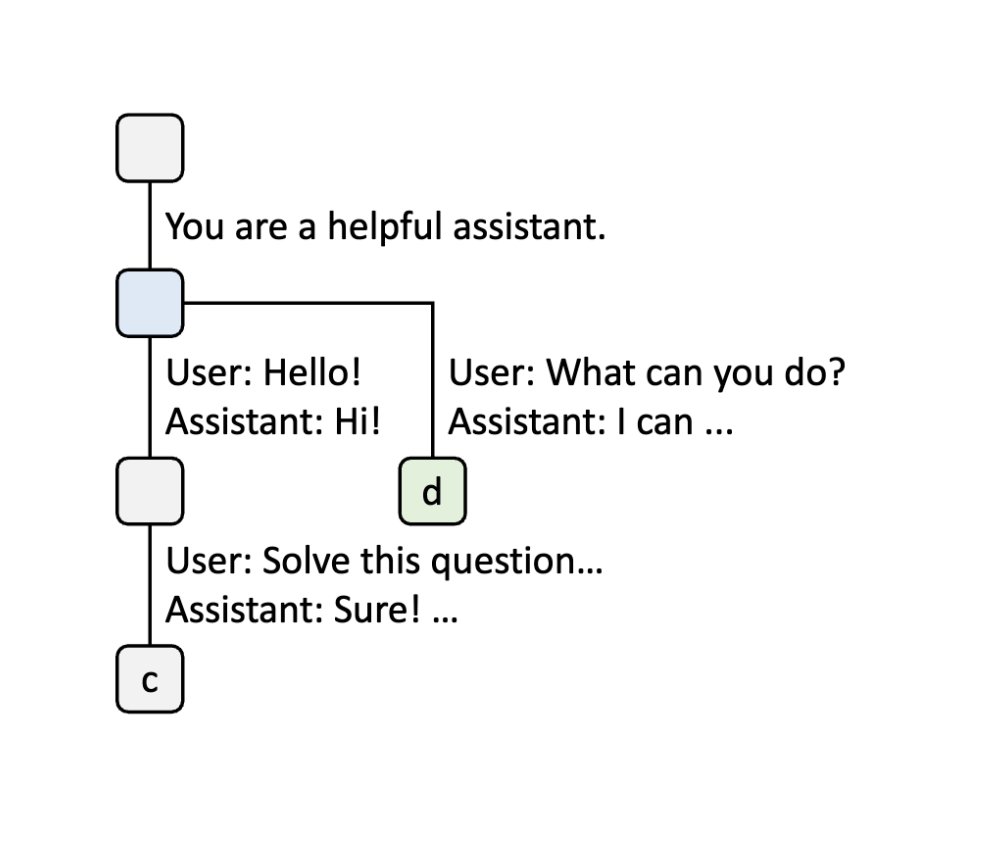
Step 4: Branching for New Sessions
When a new chat session begins, the node is split into two nodes to allow both chat sessions to share the system prompt. This is where the real savings happen—the system prompt’s KV cache is computed only once.
Step 5: Eviction Based on Memory Constraints
Due to memory limits, some nodes must be evicted. The radix tree uses LRU (Least Recently Used) eviction to free up space while keeping the most relevant cached data.

Step 6: Few-Shot Learning Queries
When the server receives a few-shot learning query, it processes it and inserts it into the tree. The root node is split because the new query doesn’t share any prefix with existing conversation nodes.
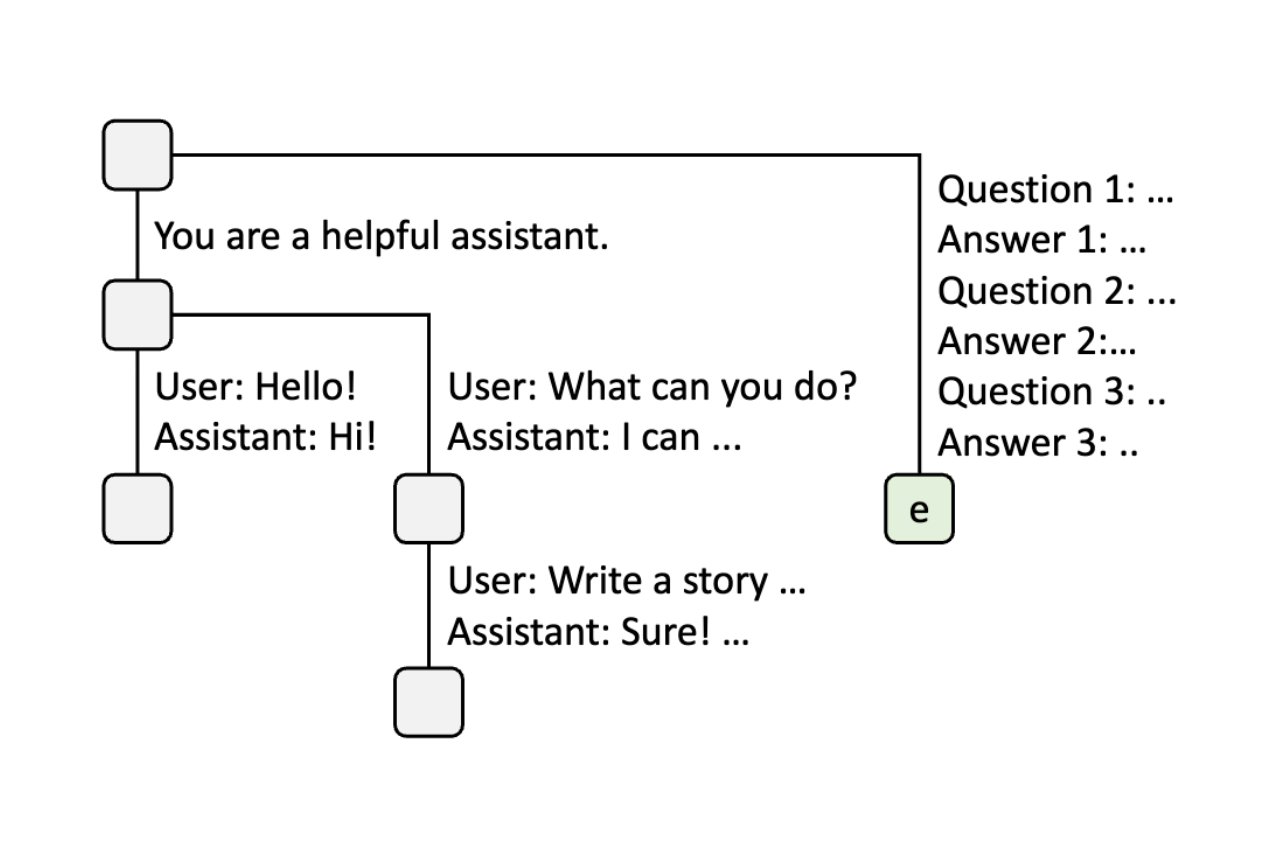
Step 7: Batch Few-Shot Learning Queries
When the server receives a batch of additional few-shot learning queries that share the same set of few-shot examples, the node is split to enable sharing of those examples across all queries.
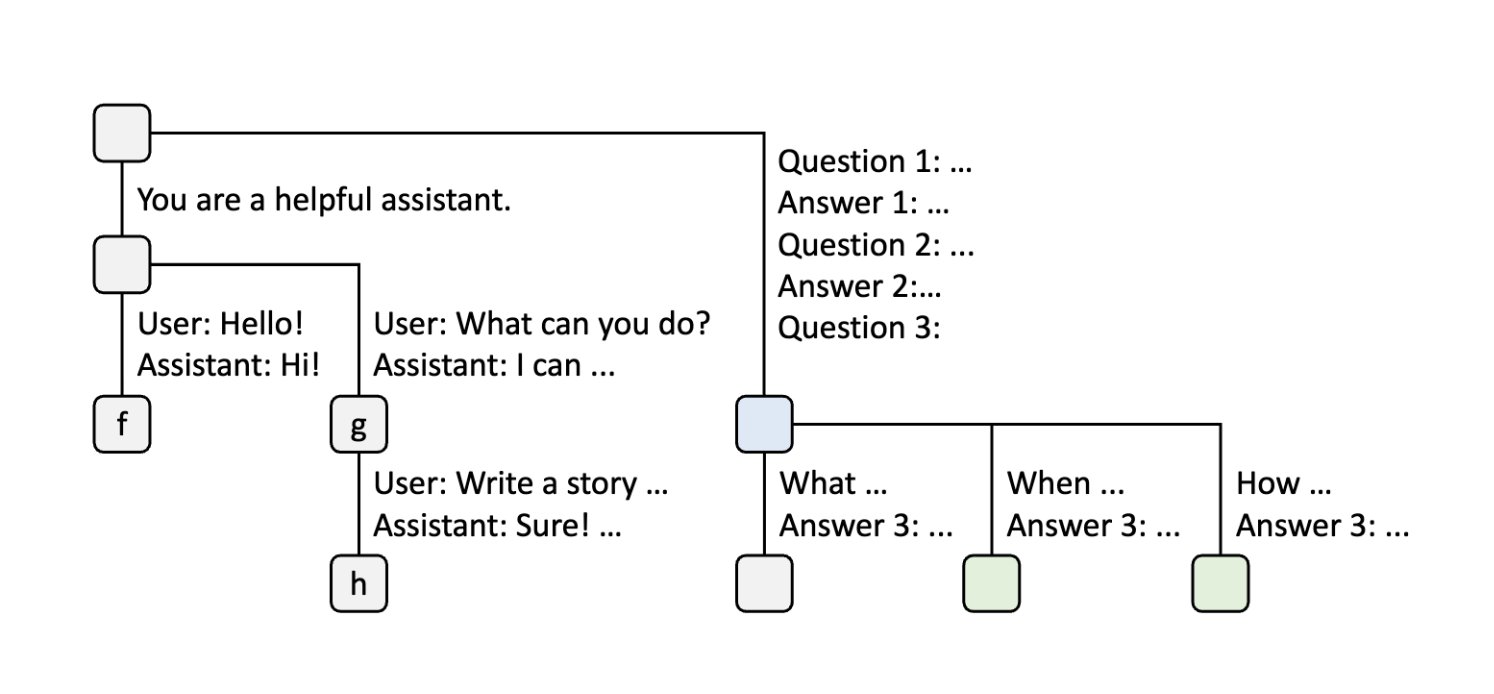
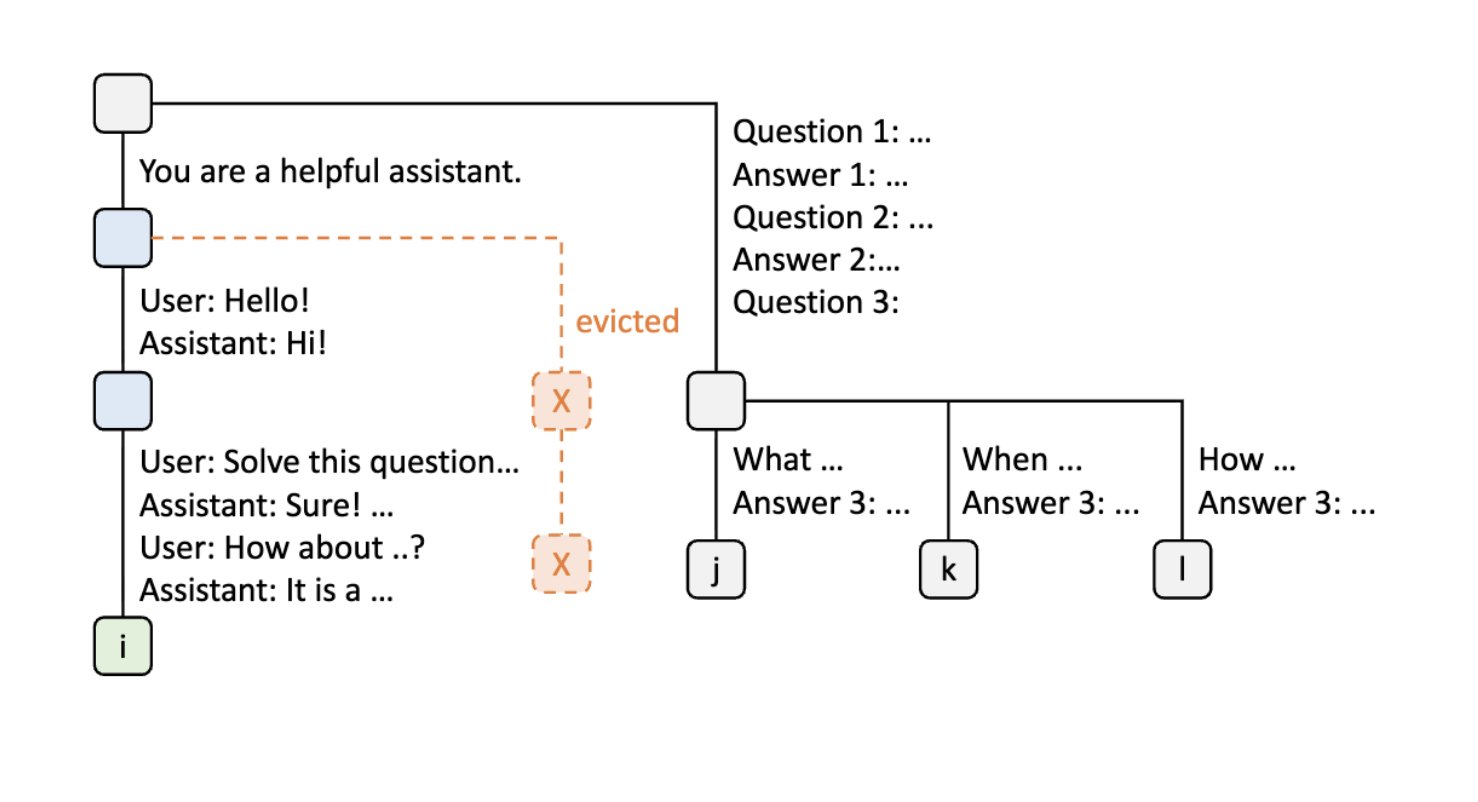
Step 8: LRU Eviction in Action
When the server receives a new message from a chat session, it may need to evict nodes from other sessions based on LRU policy to make room.
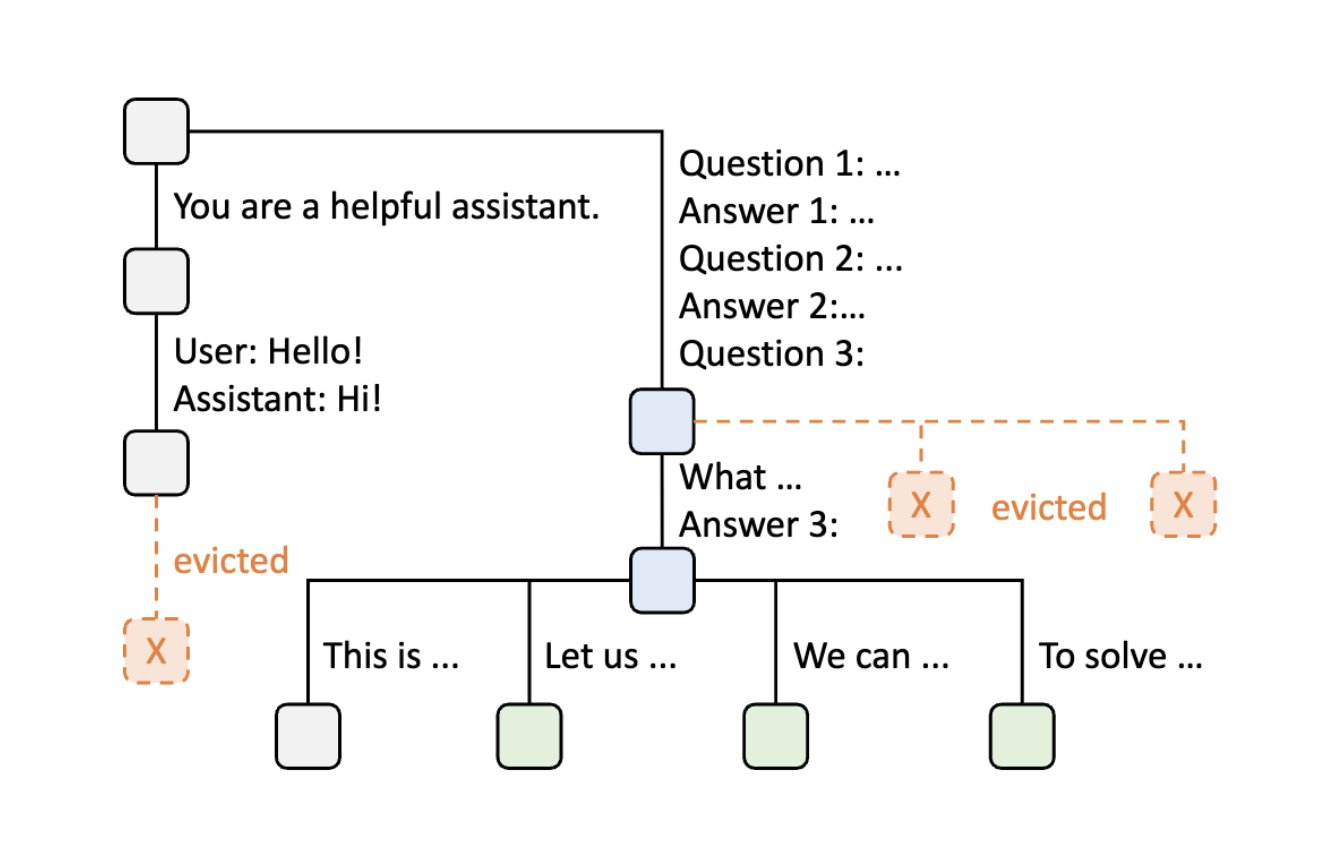
Step 9: Self-Consistency Sampling
For self-consistency prompting, the server can sample multiple answers for the same question. The radix tree efficiently handles this by creating multiple branches from the same prompt node.
The Beauty of Automatic Adaptation
The radix tree intelligently adapts to user requests with no manual configuration required.
Mini-SGLang implements this data structure in the RadixCacheManager, which is used in the main scheduler for:
- Prefix matching: Finding cached prefixes for incoming requests via
cache_manager.match_req() - Cache allocation: Allocating cache slots for new tokens via
cache_manager.allocate() - Cache cleanup: Freeing and caching completed requests via
cache_manager.free_and_cache_finished_req()
Overlap Scheduling: Maximizing GPU Utilization
LLM inference runs on GPU, but the CPU still needs to do substantial work:
- Match prefixes in radix tree
- Allocate memory for KV caches
- Schedule next batch of requests
An unoptimized inference engine can spend as much as half of its time on CPU overhead.
The Problem with Sequential Scheduling
Traditional inference systems perform work sequentially. CPU scheduling overhead can consume 20-50 ms in high-throughput scenarios. For GPU batches that finish in 100 ms, this represents 20-50% of the total time wasted with the GPU sitting idle.
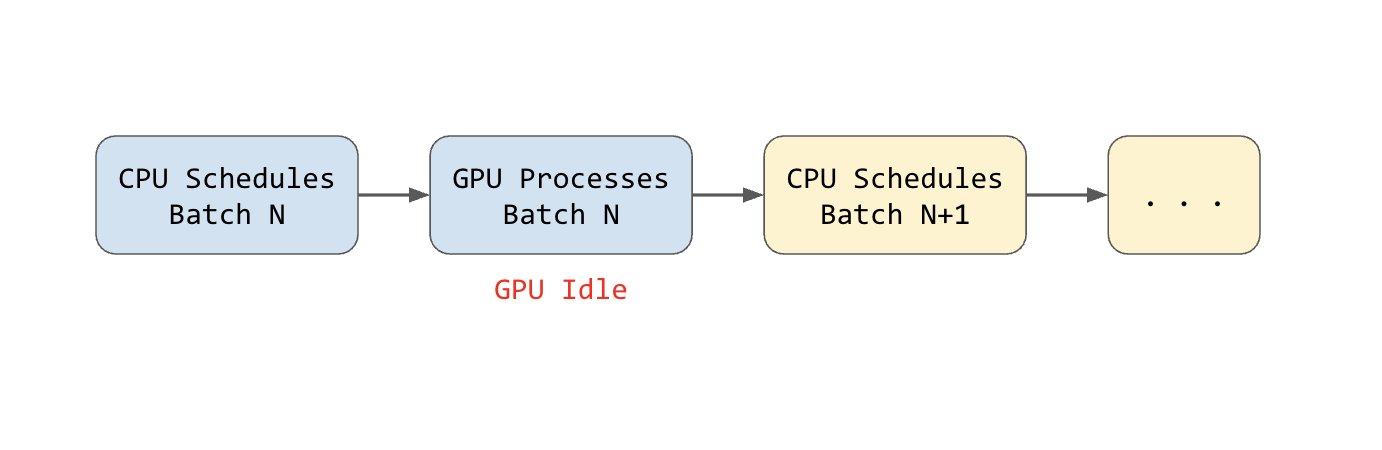
The Solution: Overlap Scheduling
The idea of “overlap scheduling” is to overlap the CPU scheduling with GPU computation.
The scheduler runs one batch ahead, precomputing all the necessary metadata for the upcoming batch. This approach keeps the GPUs continuously utilized and effectively hides costly overheads, such as radix cache operations.
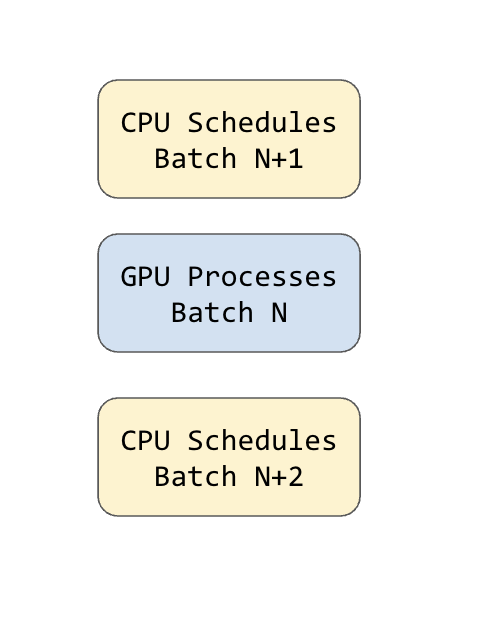
SGLang borrowed this idea from the NanoFlow paper.
Future Tokens: The Key Insight
How does SGLang prepare batch N+1 when we don’t know the output of batch N yet?
This is where “future tokens” come into the picture. Future tokens create placeholders that get filled asynchronously once generation completes. This involves precise scheduling of CUDA events and synchronization points.

The result: >95% GPU utilization even in high-throughput scenarios.
You can see the implementation in Mini-SGLang’s scheduler.
Conclusion
These two optimizations—RadixAttention and Overlap Scheduling—work together to make SGLang one of the most efficient LLM inference engines available. The radix tree eliminates redundant KV cache computation, while overlap scheduling ensures the GPU is never waiting for the CPU.
If you’re interested in learning more, I highly recommend exploring the Mini-SGLang repository, which provides a simplified implementation that’s easier to understand.
References
Papers
Official Blog Posts
- SGLang v0.4 Release Blog
- Mini-SGLang Blog Post
- SGLang Introduction Blog
- Scheduling Overhead in LLM Inference
Tutorials & Articles
- SGLang: How a Secret Weapon is Turbocharging LLM Inference (Medium)
- SGLang: Efficient LLM Workflows (Hugging Face)
- SGLang Talk (SlidesLive)